文常懿 王继荣 田宏志 李 军
(1.青岛大学a.机电工程学院;b.计算机科学技术学院,山东 青岛 266071;2.青岛大学威海创新研究院,山东 威海 264200)
20世纪80年代,以美国为首的发达国家将计算机技术应用到养殖领域[1],近年来我国养殖业发展迅猛,现代化养殖模式逐渐兴起。在大规模养殖场的日常管理、资产清点和养殖过程中,对猪只数量的盘点非常关键[2]。传统饲养模式主要依靠饲养人员肉眼观察进行猪只盘点,耗费大量的人力物力,且效率低。随着计算机视觉技术的快速发展,基于深度学习的卷积神经网络(convolutional neural network,CNN)广泛应用于图像处理领域[3],基于深度学习计数方法的相关研究也日益增多,逐渐应用于猪只识别及计数领域。高云等人[4-5]对Mask R-CNN 网络结构进行改进,在原网络基础上将网络框架加深加宽,得到优化的网络模型Pig Net,提升了对存在粘连的猪体识别效果;高云等人[6]对高密度猪只计数进行研究,在人群计数网络CSRNet[7]中添加金字塔结构,建立猪只计数网络(pig counting net,PCN),在训练与优化后得到猪只计数模型。与改进的计数卷积神经网络(counting CNN)模型相比,PCN 与多层神经网络[8](multi-column convolutional neural network,MCNN)、CSRNet均拥有较高的鲁棒性和准确性;杨阿庆等人[9]对母猪的个体分割进行研究,提出一种基于全卷积网络[10](fully convolutional networks,FCN)算法,以VGG16为基础网络,FCN-8s为跳跃网络结构,建立FCN-8s-VGG16母猪图像分割网络,在形态学处理后对母猪图像分割准确率达99.28%;胡云鸽等人[11]对Mask R-CNN 网络进行改进,修改特征金字塔网络[12](feature pyramid networks,FPN),提高了对模糊边缘的识别率,对12~22只生猪的猪舍计数精度达98%,对存在80只生猪的猪舍计数精度达86%;王荣等人[13]提出一种通过识别猪只脸部特征确定猪只身份的识别模型,利用图像均方误差(mean square erro,MSE)和结构相似性(structural similarity index,SSIM)对数据集进行筛选,防止因数据集相似而过拟合;TIAN M 等人[14]根据ResNet结构修改了Counting CNN 模型,从图像特征映射到密度图,通过集成密度图获得整个图像中猪的总数;CHEN G 等人[15]通过深度卷积神经网络检测猪体的部分关键点对猪只进行识别,提出一种新的空间感知时间响应滤波(spatial-aware temporal response filtering,STRF)方法预测猪的数量,有效抑制了因猪只、相机运动和跟踪故障引起误报。因此,本文提出了一种基于YOLOv5的猪只盘点方法,以实验猪场采集的数据为基础,添加网络收集猪只图像制作数据集,以YOLOv5s为训练框架用数据集进行训练,将得到的训练模型嵌入Jetson Nano开发板上,通过对网络摄像头实时采集视频进行识别,实现猪只盘点。该研究经济高效,具有广阔的应用前景。
基于YOLOv5s的猪只盘点系统整体框架如图1所示。六间猪舍上方分别安装网络摄像头,采集猪舍图像制作数据集,基于YOLOv5s为训练框架进行训练,训练后的YOLOv5模型嵌入Jetson Nano开发板。由于摄像头采用鱼眼摄像头,视野范围较宽,画面边缘还会出现邻接猪舍,Jetson Nano开发板在接收到图像后首先将需要计数的猪舍区域进行划分,再对区域内的猪只进行计数。

图1 基于YOLOv5s的猪只盘点系统整体框架
2015年,YOLO[17]首次将目标检测重新定义为回归问题并在单个神经网络中执行[16],该系列是一种端到端的一阶段目标检测算法,与前代 YOLOv4 相比,YOLOv5的检测速度与准确性都得到了提升。YOLOv5系列包含4种模型,即YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,其中YOLOv5s模型的深度和特征图宽度最小。本实验将最终训练所得模型嵌入jetson nano开发板,考虑到开发板的性能,选用YOLOv5s作为该实验的网络模型,以满足实验对于网络模型轻量化和检测速度的要求。YOLOv5网络结构如图2所示,该网络结构由输入端(Input)、主干网络(Backbone)、Neck网络和输出端(Prediction)4部分组成。

图2 YOLOv5网络结构
2.1 输入端
YOLOv5输入端包括Mosaic数据增强、自适应锚框计算和自适应图片缩放3部分。Mosaic数据增强将4张图片进行随机缩放、裁剪、排布操作后拼接成一幅图像进行训练,此方法丰富了检测物体的背景且增加了小目标,提高了网络的鲁棒性。自适应锚框计算是指在网络训练阶段,YOLOv5模型针对不同的数据集,设定初始长宽的锚框,在初始锚点框的基础上输出对应的预测框,再与真实框对比并计算两者之间的交并比(intersection over union,IOU),反向迭代网络参数,从而更新整个网络的参数。由于输入图像大小尺寸不同,YOLOv5采用Letterbox自适应图片缩放技术将输入图片缩放至统一大小,常用尺寸有640像素×640像素、416像素×416像素等。
2.2 主干网络
YOLOv5的主干网络由Focus结构和CSP 结构2部分组成,Focus结构是YOLOv5中的输入图片进入主干网络前通过切片操作进行裁剪,在图像中每隔一个像素进行取值,得到4个独立的特征层,将其进行堆叠,宽高信息集中到通道信息,输入通道扩充4倍,即拼接起来的图片由原先的RGB 3通道变成了12通道,再对图片进行卷积操作,最终得到没有信息丢失的二倍下采样特征图。YOLOv5使用CSPNet[18](cross stage partial networks)作为Backbone,设计了2种CSP结构,其中CSP1_X 结构应用于Backbone部分,另一种CSP2_X 结构则应用于Neck网络中。
2.3 Neck网络
YOLOv5的Neck网络为特征融合网络,使用了FPN+PAN 结构,YOLOv5的Neck网络采用CSP2结构,加强了网络特征融合能力。FPN 是一种加强主干网络CNN 特征表达的方法,通过利用常规CNN 模型内部从底至上各个层对同一规格图片不同维度的特征表达结构。路径聚合网络(path aggregation network,PAN)是在FPN 上采样融合特征金字塔之后,又增加了一个下采样融合的特征金字塔。
2.4 输出端
输出端的作用主要是对输入特征图进行预测输出,目标检测任务的损失函数一般由分类损失函数(classification loss)和回归损失函数(bounding box regression loss)2部分构成,YOLOv5采用CIOU_Loss作为Bounding box的损失函数。早期使用的IOU_Loss是根据IOU 的损失函数:
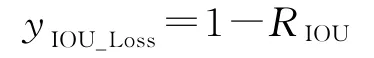
在计算预测框与目标框的损失时,当预测框和目标框不相交,即IOU=0时,IOU_Loss无法进行优化,IOU_Loss同时也无法区分2个数值相同但相交情况不同的IOU。在IOU 的基础上,GIOU_Loss增加了相交尺度的衡量方式,解决了边界框不重合时的问题[19]。DIOU_Loss在IOU 和GIOU 的基础上,考虑边界框中心点距离的信息,解决了GIOU 有时无法区分预测框和目标框相对位置关系的问题[20]。而CIOU_Loss在DIOU 的基础上,考虑边界框宽高比的尺度信息,使预测框回归的速度和精度更高。
本研究在工作站搭建YOLOv5实验环境,采集实验猪场的猪舍图像和网络收集猪舍图像,使用vott标注工具对采集图像进行多边形标注,创建数据训练集与测试集,将训练集用于YOLOv5模型,训练得到最佳训练模型,将测试集用于最佳训练模型的测试并得到测试结果。最后修改YOLOv5检测环节,实现分区域识别和检测框,统计猪只计数。
3.1 实验环境
实验环境配置如表1所示。

表1 实验环境配置
3.2 数据集制作
采集实验猪厂猪舍内监控摄像头图像和网络收集猪舍图像制作数据集,设置格式为VOC 数据集格式。猪舍内监控摄像头为萤石互联网云台相机,型号为CS-C6CN-1C2WFR-C,分辨率为1 920像素×1 080像素,采集图像共计2 000张,剔除有污迹和猪只重叠的图像,剩余1 700张;网络收集图像1 300张,与摄像头采集图像共计3 000张组成数据集,使用vott标注工具对采集图像进行标注。
3.3 模型训练及结果分析
将输入图像的尺寸设置为640像素×640像素,迭代次数设置为300,迭代批量设置为16,使用数据集对YOLOv5s框架进行训练,训练完成后根据结果中的数据绘制查准率和召回率曲线,训练模型参数如图3所示,根据实验结果绘制精确率曲线和m AP0.5曲线,训练结果参数如图4所示。
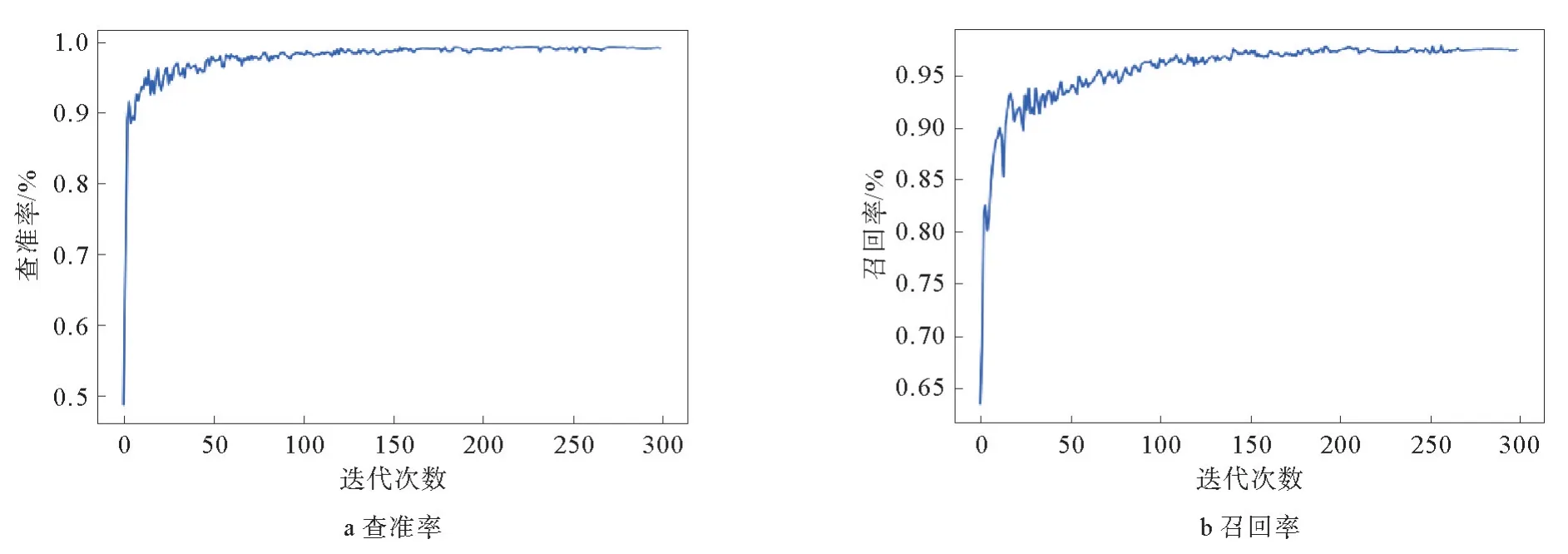
图3 训练模型参数
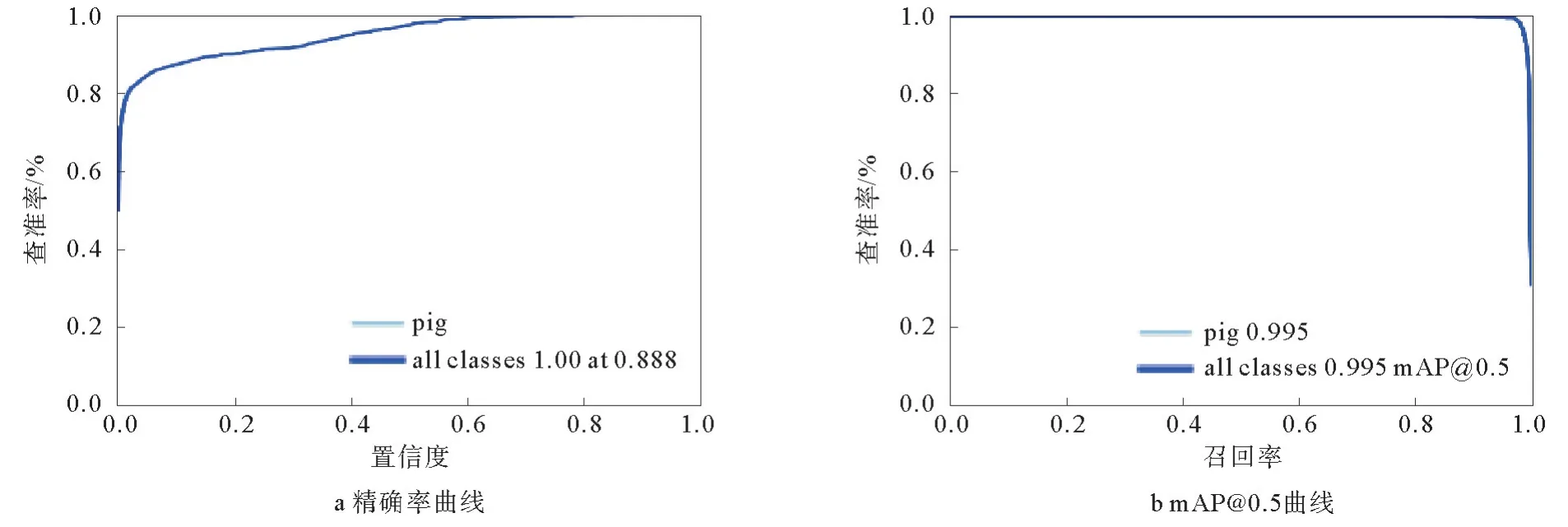
图4 训练结果参数
分别使用相同数据源对2组模型进行测试,由添加网络图像组的训练模型能识别出某些画面边缘的猪只,而未添加组不能识别,模型测试结果如图5所示。

图5 模型测试结果
使用仅猪场采集图像作为数据集对YOLOv5s模型进行训练,与添加了网络图像作为数据集进行训练的结果进行对比,2组模型训练结果对比如表2所示。
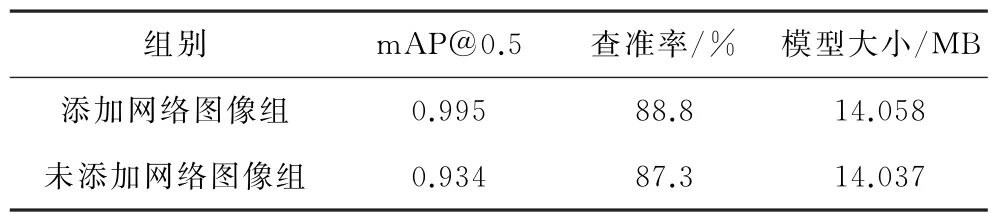
表2 2组模型训练结果对比
实验结果表明,添加了网络图像进行训练的模型,其m AP@0.5和查准率指标均优于未添加网络图像组训练的模型,对猪只的识别效果更优。同时,训练模型大小几乎没有增加,保证了训练模型的轻量化,因此采用添加网络图像作为数据集的训练模型为最优训练模型。
使用上述训练得到的最优模型嵌入Jetson Nano开发板,接入实验猪舍上方摄像头的视频流,对试验猪舍进行猪只划分,两栏猪舍分别单独计数,每栏9头生猪,设置置信度Confidence为0.8盘点,在猪只分散情况下,白天识别准确率达95.8%,白天计数实验图如图6所示。同时进行夜间计数实验,单栏17头生猪,设置置信度为0.8,夜间识别准确率达86%。夜间计数实验图如图7所示。

图6 白天计数实验图

图7 夜间计数实验图
本文应用YOLOv5目标检测模型,研究了现代化智慧养殖模式中猪只盘点的实现方法。采集试验场地猪舍图像和网络猪舍图像,制作数据集作为共同训练模型,与单一试验场地猪舍图像作为数据集相比,该模型拥有更高的识别率,白天猪只识别准确率达95.8%,夜间识别准确率达86%。选用YOLOv5s进行训练,得到大小仅14.058 MB的训练模型,在满足识别准确率的前提下,该模型更加轻量化且检测速度更快,平均检测速度达80帧/s。该模型嵌入Jetson Nano开发板,可同时对6间猪舍进行猪只盘点,相比人工盘点,该方法更加经济高效,应用前景更广阔。但该算法在猪只被遮挡面积过大的情况下,识别率较低,导致计数出现偏差,下一步研究重点是在目标检测的基础上,增加目标追踪算法,为每头检测出的猪只编号并追踪。
猜你喜欢盘点猪只猪舍降低日粮粗蛋白并添加单体氨基酸对断奶—育肥猪生长性能和营养排泄的影响(中)猪业科学(2022年11期)2022-12-17母猪怀孕后如何控制猪舍环境河南畜牧兽医(2021年3期)2021-01-06猪胃溃疡的病因与防治措施中国畜禽种业(2020年4期)2020-12-16睁眼瞎盘点动漫星空(2020年10期)2020-10-29冬季猪舍有啥讲究河南畜牧兽医(2020年19期)2020-01-10秋冬季防应激不可忽略饮水消毒河南畜牧兽医(2020年21期)2020-01-10猪只硒缺乏症的预防措施和治疗方法猪业科学(2018年5期)2018-07-17盘点与展望新农业(2016年13期)2016-08-16标准化猪舍设计技术兽医导刊(2016年6期)2016-05-17新型帐篷式猪舍的使用猪业科学(2015年6期)2015-12-26


